I started a quick throw-away artwork just as a demonstration of some of the ways img2img and inpainting works within Stable Diffusion, via the Automatic1111 webUI (off-line installation).
I tried to pick something that was fantastic enough that it wouldn't get too hung up on trying to make the tech look plausible or the coke bottles the right shape, something that didn't have obvious ambiguities the AI language parser would get hung up on, and that wasn't layered or a complex pose or something that would be difficult to stack (like my first idea, which was a sort of typical golden age SF cover of a guy in a space suit with a blaster in foreground, a spaceship and barren planet/moon surface behind him).
So went for a retro, well, pretty specifically Love and Rockets sort of flying bike thing.
Here's what the AI is spitting out when I tried to do it with prompts alone (aka the txt2img mode):

Nice details and a lot of surface gloss, but what the hell is that thing? It's also not the classic racing motorbike pose that these flying motorbikes seem to attract.
So better to rough out the composition in paint first:

That is actually too detailed. Really, the less you put in, the better the AI is at working things out. Among other things, your way of drawing a shape won't be its way of drawing a shape, and even to get at the same end point you are better off handing it less to begin with.
Similarly, the first prompt was pretty bare-bones:
(That checkpoint is a fork off SDXL, but doesn't require the weird two-passes approach of the latter.)
First pass of img2img, with a denoising of .4 or thereabouts:

Yeah, I ran it about a dozen times, keeping the one that preserved more of the details I cared about, and sacrificing others. That's the trouble with doing things in this mode, with a single pass.
The more powerful mode is inpainting and selecting just part of an image. For which you also get to change the denoising level, plus you can edit the prompt to reflect just the part of the image you are trying to iterate on:
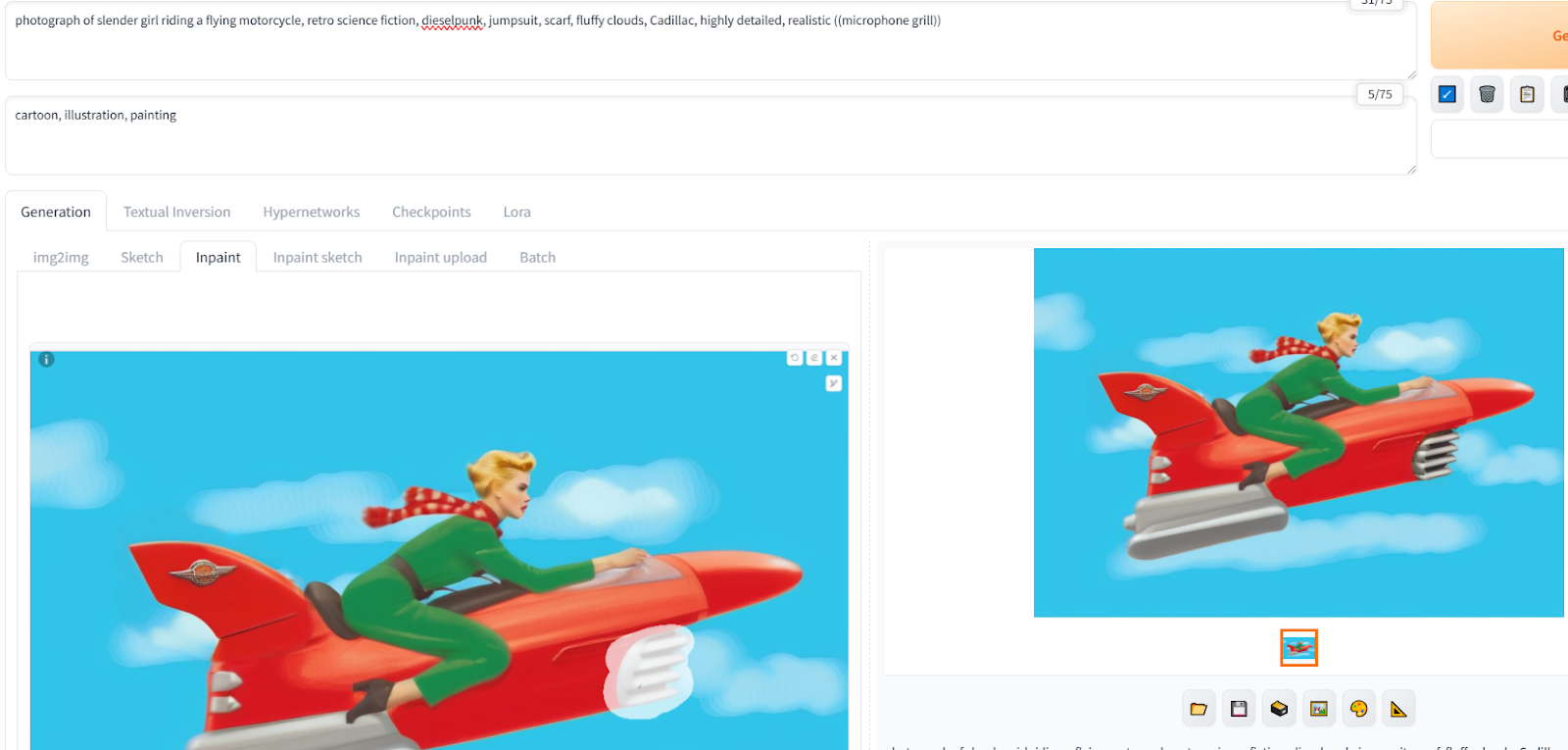
Also an example of prompt engineering. Things like automobile grill or air intake wasn't leading the AI in the right directions, Fortunately the model I was using was sensitive to vintage stuff, so a reference to the famed Shure-55 (not by name), triggered the look I was after.
I also canned dieselpunk and Cadillac pretty quickly. The latter kept adding a caddy logo to things. The former turned out not to be in the language model but it did seem to be hauling "punk" out of it and was starting to add mohawk and piercings.
At various stages bits had gotten too far off what I was after. Like that fin -- that one, I used the built-in paint window in Automatic1111 to slap red paint over the hood ornament and forced a re-render of a different look.

But...what would happen to it if I stayed in img2img and rolled the denoising up past .5 ? (as a very rough guide, and it depends quite a bit on the model and less, but still there, on how easy that specific image is for the AI to interpret, up to .3 is a "clean up," at .4 it begins to change things, and somewhere just before .7 it "snaps" and gives up completely on respecting the original image, making up something new that only vaguely resembles the colors and masses.)

But this does show the basic ideas are imbedded into the training data; there are stereotypical elements like the hotrod paint job or the fluffy white clouds that the AI puts in there even without me specifying those (the first image, after all, did not include the cloud background in the prompt. The AI put it in because that's what this sort of image usually gets).
So plausible. Try a few more runs and see what happens:

So back to inpainting. That fin wasn't working, the jets had gotten just stupid...but I knew those were easy fixes. The "magic words" to fix the air intake, after I'd roughly painted out most of it with blue sky and sketched in a better shape, was "P-51." For the jets, "contrail" and "afterburner," even if I did have to make a second pass to remove a Blue Angel that snuck in there.
And that is where I really stopped.

(This is AI, and furthermore, the modified SDXL and one LoRA I used during a few trouble-spots -- not specific to flying rockets or retro SF in particular, just one that was good at this sort of illustration look -- are via Civitai therefore even more copyright-violating than the original SD training data. I present these under the shade of "academic or criticism" as my sop towards fair use.)
No comments:
Post a Comment